最近花了大量的时间研究算法、python编程的应用和kaggle/阿里天池的比赛,对于最基础的sql有些忽略,作为数据分析师的入门工具,必须要时常回顾一下。这篇文章将对sql进行一个总结概括,并且对自己在leetcode、牛客网以及sql50题练习中学到的一些实用的知识点进行复习。
这篇文章旨在从我个人觉得比较实用的sql角度进行归纳,因为很多企业都是在实用hive,因此大部分内容都是基于hive/sql而言的。
至于理论和背景知识方面,本文不进行过多的展开,网上有大量的文章和视屏对此进行讲解,大家可以自行搜索。以下这篇文章对于hive/sql有很多基础的讲解,这里我放着供参考。
Hive详解 - 会飞的猪仔 - 博客园www.cnblogs.com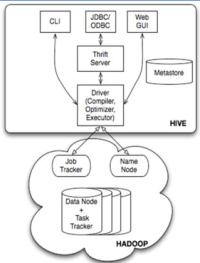
基本介绍
- hive和sql的简单介绍
sql全称为Structured Query Language,翻译成中文就是结构化查询语言,是一种专门用于数据查询、更新和管理关系数据系统的语言。而Hive是基于Hadoop的一个数据仓库工具,用来进行数据的提取转换和加载。其可以将结构化的数据文件映射成为数据仓库表,并且提供类Sql的查询功能,将sql语句转换成mapreduce任务运行。简而言之,sql是一门语言,但hive是一个数据仓库工具(好像有的时候面试会问两者的不同)。
2. hive的基本显示命令
show databases 查看所有的数据库
show tables查看所有的表
show partitions查看所有的分区
show functions显示能够使用的功能函数
descformatted table_name显示表的详细信息
show create table table_name显示建表语句
3. hive的数据结构
hive中有三种复杂数据类型结构,分别为struct/map/array。
- struct可以用“字段名.数据”的方式来获取,有点类似pandas查看某一个数据的时候,用df.user_id这种。
- map简单一点可以理解为python中的字典,是一种键值的组合,可以用字段名.[]的方式来取值。
- array相信用过pandas的同学应该比较数据,它是相同类型和名称的变量的集合,可以使用字段名.[1]方式来获取数据。
增删改/数据导入、导出
对于hive的增删改和hive的数据导入和导出而言,作为数据分析人员一般不会用到,更多的是根据已有的表格进行一些数据的聚合,从而得出一些结论,这边就做一个大概的描述。
- 建表语句(方括号中的内容都是可有可无的)
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name #external是外部表的意思,对于内外部表不理解和熟悉的同学可以自行搜索一下,if not exists是否表格已存在,一般建表的时候都会加上,防止建立的表格重名,导致无法建立。
(col_name data_type [COMMENT col_comment], ...)
[COMMENT table_comment] #对于表格的描述,一般都会加,比如说“销售信息表”等
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]#这边是否对表格进行分区
[CLUSTERED BY (col_name, col_name, ...) #是否进行分桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] #排序
[ROW FORMAT row_format] #数据之间的间隔区分
[STORED AS file_format] #保存格式,一般可以选择textfile,如果数据需要压缩,使用 STORED AS SEQUENCEFILE
[LOCATION hdfs_path] #指定文件路径
这里补充一下分区和分桶的区别。分区就像是建立文件夹的过成,对于一个太大的数据。通常需要按照日期来进行分区,这样大家在查询的时候可以直接加上条件语句where XXX=XXX时间,来缩小数据查询的范围和增加查询的效率。
但是如果数据量比较大的情况下,分区都可能导致处理效率不高,这个时候就需要考虑分桶,所谓的分桶其实是更为细粒度的数据范围划分,比如说划分到每一天的数据量都比较大的时候,这时候我们可能就会根据用的id进行进一步的划分,例如1~100为一组,101~200为一组,这样查询的时候可以加上一个where id between 1 and 100,来进一步的限制范围。
2. 增删改
一般情况下,作为数据分析人员很少会用到hive中的增删改,这里大家只要做一个了解就行。
- 增加: hive中插入的情况总共分为3种:1. 基本插入,2. 多插入, 3.动态分区插入。
首先我们来看一下基本插入,其与mysql没有太多的区别,就是将一个表中的数据插入到一张新表之中,需要注意的是这里的insert into和mysql中的是有区别的,这里是指向表中追加数据。如果使用overwirte的话,新数据会将原表的旧数据覆盖。
INSERT INTO|OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
接下来是多插入模式,所谓的多插入模式是指我们可以对原表扫描一遍就可以生成多种不同的输出:
FROM frometable1(fromtable2....)
INSERT INTO|OVERWRITE TABLE desttable1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT INTO|OVERWRITE TABLE desttable2 [PARTITION ...] select_statement2] ...
最后是动态分区插入,一般情况下不建议使用动态分区插入,因为需要扫描的数据太多也不精确,非要使用的话建议动静结合(静态分区一定要放在动态分区前面!查询的时候)。所谓的动态分区插入就是不指定确定的分区的值,而只确定分区。比如说我确定要按照时间去查询,但是并不精确到某个月活着某个季度。
INSERT INTO|OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
- 删除:hive中的删除包含两个部分,一种是删除表的数据但是保留表,一种是直接删除整个表。
truncate table table_name(保留表结构),drop table table_name(删除数据和表结构)
- 修改:一般用作增加一列数据、修改列名称、增加/减少分区等功能,这个作为了解就可以。
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
ALTER TABLE table_name ADD|DROP [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ]
查询常用的技巧以及函数
一般而言我们可以将函数分为关系运算/数学运算/逻辑运算/日期函数/条件函数/字符串函数/集合函数,这里我根据自己的情况,总结了一下实用一点的函数和技巧,就不一一展开了。详细的所有函数和方法,大家可以参考下面这篇文章:
https://blog.csdn.net/doveyoung8/article/details/80014442blog.csdn.net针对查询和函数这一块内容,面对一道题目或者一个业务需求的时候,我的步骤一般是1.拆分需求成小需求,2.根据小需求写足够简单的语句,3.试验每条语句是否可行,4.将足够简单的语句拼凑在一起并进行优化,5.记录下常用的查询语句,之后使用的时候想想能不能优化。一般情况下,若是要想着从头到尾写出一个完成的复杂查询语句对于小白来说不可能,我们要做的就是一步一步走,等你写的足够熟练之后,可能一下子就能写出一条非常复杂的语句。比如说在leetcode615题(部门与公司平均工资比较)。我们可以将数据拆分成三块1.公司本月的平均工资,2.部门本月的平均工资,3.使用case when或者if进行两个对比。这样就能够将一个大的需求化为一个个小的需求,最后整合起来。
- 数据类型的转换
cast(字段 as 数据类型),这是一个相对常用的函数,能够帮助你进行不同类型的数据转换,很多时候日期类的数据可能存储的形式为string类型或者数字类型,但是你使用的时候是日期函数类型,这个时候你就需要进行转换。
- 利用case when进行行列互换或者条件筛选
可以练习的题目leetcode上的608/618,以及sql50题中也有涉及行列转换。我们以下面这道题目为例:
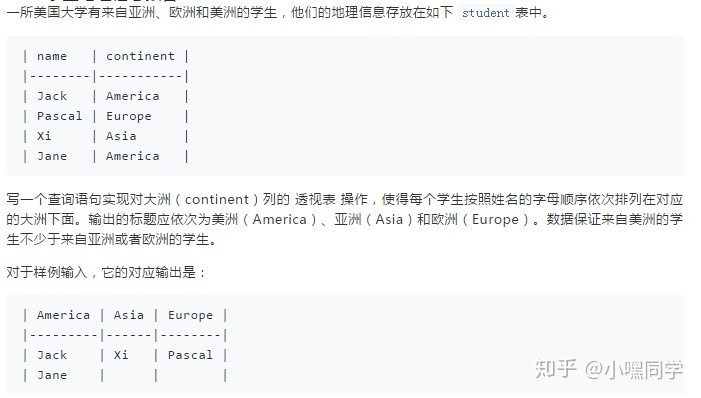
针对这种类型的行列转换,我们首先想到是用case when的语法将行上的内容转换为竖着的内容,然后去除每一行存在的空值就行。具体实现的sql可以参考如下:
select d.a as America, d.b as Asia, d.c as Europe from (select rn,
max(case when continent = 'America' then name else '' end) a
max(case when continent = 'Asia' then name else '' end)b
max(case when continent ='Europe' then name else '' end)c from
(select student.*, row_number() over (partition by continent order by name) from student ) group by rn) d order by a, b, c
这里之所以会用rn是用来确定行列转换后的行数,保证每一行上都有对应的数据。感兴趣的同学也可以自己去leetcode上练习一下。
- 日期函数
日期函数主要包含两个部分1.数据类型的转换和变化 2.日期的一些简单计算。首先我们来看一下日期数据类型的转换,一般而言,日期数据类型的转换和变化主要涉及到fromunixtime和unixtimestamp的连用。其中unixtimestamp(string date)能够将文本形的数据转换为bigint类型,然后在通过fromunxitime(bigint unixtime, stringformat['yyyyMMdd'])来转换成你需要类型时间格式。在mysql中可以使用to_char(日期,stringformat['yyyyMMdd'])来转换时间的格式,但是在hive中不知道能不能用,改天实验一下。
其次对于日期的简单计算,一般会涉及到datediff(日期1,日期2)查看两个日期之间的间隔,比如说我们要取最近30天的数据的时候,可以使用datediff(current timestamp ,target_time)<=30 。还可以使用date_add(日期1,增加的天数)和date_sub(日期2,减少的天数)进行日期之间的增减,一般我们可以进行当前日期的减少或者过去日期的增加来进行同比分析和环比分析。比如说我们要同比对比去年的时候,那么我们可以对去年的日期加上365天,然后用日期方式将两个表join在一起,销售量之间的变化就能显而易见。
除此以外还可以使用year(), month(), weekofyear()等返回当前日期的年、月、日等信息,用于分析。
- 巧用错位
实际应用中,我们经常会遇到求连续3天以上销量超过多少,或者连续多少天活跃用户超过多少。最简单一点影院中连续的3个以上的座位等等。对于这类题目我们都需要巧用错位的方式来达到我们的目的。比如上面日期函数中讲的date_add和date_sub其实就是错位的一种形式。在其他应用中,我们也要想着怎么错位能够达成我们的目的,比如说在leetcode上这道题目:

针对这种类型的题目,简单一点的方法就是用三张表a,b,c然后每张表的人数都是大于100的设定好条件,其次加3张表join在一起然后用id-1和id+1的方式进行错位。但是这种方式存在一个问题,假设某天为需要看连续4天、连续5天,那么我们之前的方法显然没有太多的延展性,这时候我们就需要思考一种可以延展到所有通用的方法上去,可以参考如下:
select id, to_char(visit_date, 'yyyy-mm-dd') as visit_date, people from (select id, visit_date, people, count(1) over (partition by offset) cnt from (select id, visit_date, people (row_number() over (order by id) - id) offset from stadium where people >= 100) where cnt >= 3
- 窗口函数
sum() over ()|min() over ()|max() over| avg() over () 等是基本的hive窗口函数,你可以最简单的理解为累计。注意在使用这种函数中,如果需要指定行数,需要在over的括号内加入 ROWS BETWEEN 一个时间点 AND 一个时间点,一般是前面几行或者后面几行或者当前行。我们可以使用n preceding| current row| n following | unbounded preceding(指的是包含,一般情况是不包含的)。 用这个可以控制你想计算的前后数据量。
除此以外,hive中还有一些易用的高级窗口函数: rownumer() over ()计算行数, rank() over ()这里的排名会出现重复的排名并且跳过下一个,例如1,2,2,4,其中第四名理论上是第三名,但是因为有两个第二名,则会被跳过。为了防止这种情况,可以使用dense_rank() over ()这种情况下就不会出现rank的这种情况,例如1,2,2,3···, 它会顺序的排下去。还有ntlie(n) over(),这个函数的意义在于将你需要查询的数据切成n组,并返回当前切片的值,在切片分布不均匀的情况下,默认增加第一个切片的数据量。
- 利用concat来比较两个相同字段表中不同的数据
有的时候我们需要比较两个表中不用的部分,我们可以将我们需要比较的部门连接起来,然后进行对比分析,能大大节省我们的时间。比如说:
select concat_ws(',', time,uid,type,from_uid,is_read) as m from haowodehuifu HAVING m not in(select concates(',', time,uid,type,from_uid,is_read) as m from heixionghao_wodehuifu )
这里用having的原因是因为,用where的话不能将m作为条件去判断。
- order by/sort by/distribute by/cluster by的区别
order by(全局)是对全局进行排序,sort by(局部)则是对每个reducer内部进行排序, distribute by(局部)保证同一列下面一个区间内的数据是有序的,比如说同一年的数据是有序的排列的。而cluster by则是前面两者的结合,能够实现文件的全排列。
关于hive和sql的一些总结暂时先写到这边,以后在实际接触中我会补充一些比较实用的技巧和函数。如果有问题的话,欢迎随时留言。