Spark快速大数据分析——Scala语言基础(壹)
文章目录
- Spark快速大数据分析——Scala语言基础(壹)
- 前记
- Scala的历史
- 环境搭建:
- 1、SBT构建工具和REPL:
- 2、使用IDE:
- Scala 入门:
- 一点点补充:
- Scala的脚本:
- 声明值和变量:
- 数据类型:
- Scala运算符:
- Scala的控制语句:
- Range:
- for循环:
- Scala的数据结构
- 元组和zip操作
- Zip操作
- 集合
- 类的定义:
- 辅助构造方法
- 单例对象与main
- 伴生对象:
- 方法与函数:
- 方法的定义:
- 方法的多参数列表:
- 函数简写规则
- 类的继承:
- Scala Trait(特征):
- 模式匹配
- 样例类:
前记
Spark是专为大规模数据处理而设计的快速通用的计算引擎,它是由Scala语言开发实现的,关于大数据技术,本身就是计算数据,而Scala既有面向对象组织项目工程的 能力,又具备计算数据的功能,同时Spark和Scala的紧密集成,所以学习Spark之前强烈推荐学习Scala,虽然我认为scala是一门烂语言,各种特性学起来十分折磨人,但介于Spark的强大,这里还是推荐使用Scala作为使用的语言。
Scala的历史
Scala于2001年由洛桑联邦理工学院(EPFL) 的编程方法实验室研发,它由Martin Odersky(马 丁•奥德斯基)创建。目前,许多公司依靠Java进行 的关键性业务应用转向或正在转向Scala,以提高其开发效率、应用程序的可扩展性和整体的可靠性。
Scala是Scalable Language的简称,它是一门多范式的编程语言, 其设计初衷是实现可伸缩的语言、并集成面向对象编程和函数式编程的 各种特性。
可伸缩性,简单来说,是以更大的规模来做你现在所做的事。伸展一个 Web 应用的规模在于让更多的人使用你的程序。如果你没法找出方法在伸展规模的同时提高性能,没关系。而且只要你可以伸展规模来处理更大数量的用户,那么有几个单点故障(single point of failure)也没关系。
Scala语言可以运行在Windows、Linux、Mac OS等系统上。由于Scala是运行在JVM平台上的, 所以安装Scala之前必须配置好JDK环境。具体的环境配置可以见下文。
环境搭建:
1、SBT构建工具和REPL:
SBT构建工具官网 安装 SBT,它是业内公认的构建工具。安装完成后,便可以在 Linux、OS X 终端、Windows 命令窗口中运行 sbt 命令。
打开 shell 或命令行窗口,进入示例代码解压后的目录,敲入命令 sbt test,该命令会 下载所有的依赖项,包括 Scala 编译器及第三方库。下载完毕后,sbt 会编译代码并运行单元测试。该命令最后会输出 success 信息。再次运行 sbt test 命令,由于该命令不需要执行任何事情,你会发现命令很快就结束了,当你启动 sbt 命令时,假如不指定任何任务,SBT 将启动一个交互式 REPL(REPL 是 Read、Eval、Print、Loop 的简写,代表了“读取 - 求值 - 打印 - 循环”)。
提示:如果报错JAVA version 0 请安装JDK,教程地址:JDK 安装。
JDK,SBT ,安装完成后可以看到:
执行:
sbt test
有一个警告:
No sbt.version set in project/build.properties, base directory: D:\Scalar\SBT\test
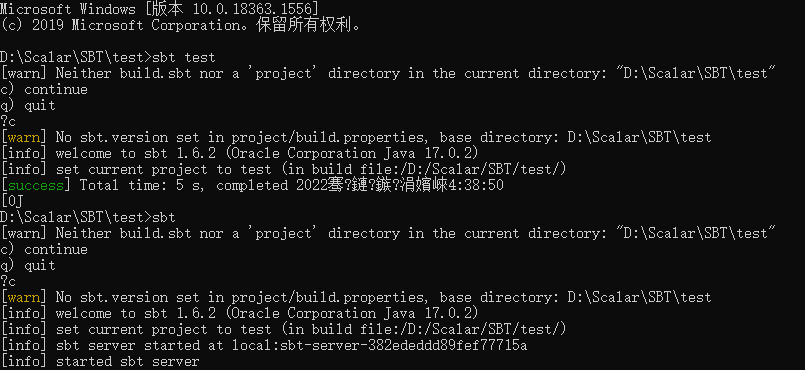
找到解决办法:
sbt sbtVersion

D:\Scalar\SBT\test>sbt sbtVersion
[info] Updated file D:\Scalar\SBT\test\project\build.properties: set sbt.version to 1.6.2
[info] welcome to sbt 1.6.2 (Oracle Corporation Java 17.0.2)
[info] loading project definition from D:\Scalar\SBT\test\project
[info] set current project to test (in build file:/D:/Scalar/SBT/test/)
[info] 1.6.2
最后通过console进入REPL
>sbt console
[info] welcome to sbt 1.6.2 (Oracle Corporation Java 17.0.2)
[info] loading project definition from D:\Scalar\SBT\test\project
[info] set current project to test (in build file:/D:/Scalar/SBT/test/)
[info] Non-compiled module 'compiler-bridge_2.12' for Scala 2.12.15. Compiling...
[info] Compilation completed in 8.133s.
[info] Starting scala interpreter...
Welcome to Scala 2.12.15 (OpenJDK 64-Bit Server VM, Java 17.0.2).
Type in expressions for evaluation. Or try :help.
执行 scala 命令时,如果未指定主程序或脚本文件,那么 **scala **将进入 REPL 模式,这与在 sbt 中运行 console 命令类似。(不过,运行 scala 时的 classpath 与执 行 console 任务的 classpath 不同。)(如 果你未独立安装 Scala,在 sbt 中执行 console 任务也能进入 Scala REPL 环境)。此时, REPL 提示符是 scala>。REPL 支持 tab 补全。
2、使用IDE:
强烈建议使用IDEA,来进行scala开发,省去很多麻烦!
Idea 社区版 2021.3.2 自带 Scala 插件,无需另行安装,但需要下载 Scala 库。在 Idea 中选择“文件”->“新建”->“项目”菜单,在打开的“新建项目”窗口 的左侧列表中选择“Scala”项目类型,在右侧的列表中选择“Idea”子类型, 然后单击“下一步”按钮,如下图所示:

在打开的窗口中输入项目名称、软件包前缀信息并选择项目使用的 Scala 库。如果是使用 Idea 第一次创建 Scala 项目,需要点击“创建”按钮,下 载并创建 Scala 库,Scala 库的版本选择 2.13.8,如下图所示:

库下载 完成以后,点击“新建项目”窗口中的“完成”按钮,完成 Scala 项目的创建,如 果创建成功,说明 Scala 开发环境配置成功。
IDEA 有另一种执行 REPL 的方式。特别是当你使用 Eclipse、IntelliJ IDEA 或 NetBeans 时,这种方式会更加实用。Eclipse 和 IDEA 支持 worksheet 功能,当你编辑 Scala 代码时,感觉不到它与正常地编辑编译代码或脚本代码有什么区别。不过一旦将该文件保 存,代码便会立刻被执行。因此,假如你需要修改并重新运行重要的代码片段,使用这种 开发方式比使用 REPL 更为方便。
具体使用见:
worksheet指南
Scala 入门:
一点点补充:
Scala的脚本:
有时我们会使用 scalac 来运行 Scala“脚本”文件,而 java 命令行却没有提供类似的功能。脚本文件的扩展名为 .sc,而编译后的文 件的扩展名为 .scala。通常,脚本文件往往也使用 .scala 扩展 名。不过如果使用 SBT 构建项目,SBT 会尝试编译这些以 scala 命名的文件,而这些脚本 文件却无法编译。脚本设计的初衷是为了简化代码,无须将声明(变量和 函数)封装在对象中便是一种简化。而将 Java 和 Scala 代码编译后,声明必须封装在对象 中(这是 JVM 字节码的需求)。scala 命令通过一个聪明的技巧解决了冲突:将脚本封装 在一个你看不到的匿名对象中。如果非要编译可以使用特殊命令:
在 scalac 命 令中传入 -Xscript 参数, 表示你所选中的 main 类,它是生成的 Java 应用程序的入口点。
关于匿名类将会在后边有机会再讨论。
声明值和变量:
Scala 有两种类型的变量,一种是使用关键字 var 声明的变量,值是可变的,另一种是关键字 val 声明的变量,也叫常量值在初始化后不可变。
var myVar : String ="Hello"
val myVal : String = "World"
提示 :Scala 遵循 Java、C#、C 等语言的注释规则,// comment 只能作用到本行行尾, 而 /* comment */ 则可以跨行。
Scala 的标识符,如方法名和变量名,中允许出现尖括号,例如定义“小于” 方法时,该方法常被命名为 <,这在 Scala 语言中是允许的,而 Java 则不允 许标识符中出现这样的字符。因此,为了避免出现歧义,Scala 使用方括号 而不是尖括号表示参数化类型,并且不允许在标识符中使用方括号,这一点等我们到了泛型的时候再来讨论。
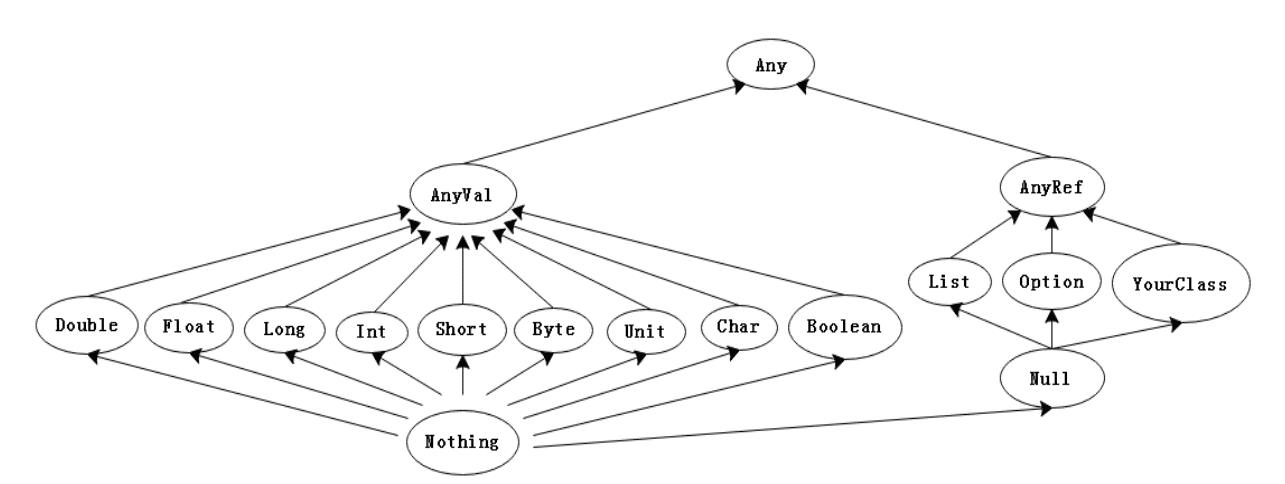
数据类型:
Scala中的所有值都有一个类型,包括数值和函数,但其数据类型都是对象,也就是说scala没有java中的原生类型。在scala是可以对数字等基础类型调用方法的。Scala 尽力使其面向对象特性更加一致,因此这些类型在 Scala 中是包含有方法的对象,就像引用类型一样。然而,Scala 编译时将这些类型尽可能地转为原生类型,使你可以得到原生类型的运行效率。
| Byte | 8位有符号补码整数。数值区间为 -128 到 127 |
|---|---|
| Short | 16位有符号补码整数。数值区间为 -32768 到 32767 |
| Int | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 |
| Float | 32 位, IEEE 754 标准的单精度浮点数 |
| Double | 64 位 IEEE 754 标准的双精度浮点数 |
| Char | 16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF |
| String | 字符序列 |
| Boolean | true或false |
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null 或空引用 |
| Nothing | Nothing类型在Scala的类层级的最底端;它是任何其他类型的子类型。 |
| Any | Any是所有其他类的超类 |
| AnyRef | AnyRef类是Scala里所有引用类(reference class)的基类 |
Scala运算符:
Scala中算术操作符(+、-、 * 、/、%)的作用和 Java是一样的,位操作符(&、|、>>、<<)也是一样 的。特别强调的是,Scala的这些操作符其实是方法。例 如,a+b其实是a.+(b)的简写。
Scala的控制语句:
Scala 也为 for 循环这一常见的控制结构提供了非常多的特性,这些 for 循环的特性被称为 for 推导式(for comprehension)或 for 表达式(for expression)。 事实上,推导式一词起源于函数式编程。它表达了这样一个理念:我们遍历一个或多个集合,对集合中的元素进行“推导”,并从中计算出新的事物,新推导出的事物往往是另一个集合。
Range:
有时我们需要一个数字序列,从某个起点到某个终点。而 Range 能满足这个需要。以下 实例将展示如何创建 Range,支持 Range 的类型包括 Int、Long、Float、Double、Char、 BigInt、和 BigDecimal
你创建的 Range 可以包含区间上限,也可以不包含区间上限;步长默认为 1,也可以指定 一个非 1 的步长:
import scala.math.BigDecimal.double2bigDecimal
//range 演示
for (i<- 1 to 10)
{
println(i)
}
output:
1
2
3
4
5
6
7
8
9
10
//不含右边界
for (i <- 1 until 10)
{
println(i)
}
output:
1
2
3
4
5
6
7
8
9
//步长为3
for (i <- 1 to 10 by 3)
{
println(i)
}
output:
1
4
7
10
//非整数步长
for (j <- 1.1 to 10.3 by 3.1 )//需要头文件支持
{
println(j)
}
output:
1.1
4.2
7.3
for循环:
基础结构如下:
for(变量<-表达式/数组/集合)
{
循环语句;
}
像 变量<-表达式 这样的表达式也被称为生成器表达式(generator expression),生成器表达式之所以叫这个名字,是因为该表达式会基于集合生成单独的数值。左箭头操作符 (<-) 用于对像列表这样的集合进行遍历。
当然可以用生成器表达式对数字区间进行访问,以这种方式编写的for更加自然。
for (i <- 1 to 10)
println(i)
output:
1
2
3
4
5
6
7
8
9
10
Scala的数据结构
Scala中包含两种数组,定长数组和变长数组,定义定长数组,需要使用new关键字,而 定义变长数组时,则需要导包import scala.collection.mutable.ArrayBuffer。
这里的定长数组指的是,数组的长度不会随着变化。。
举个例子:
>>>> var ab= new Array[Int](3)
ab: Array[Int] = Array(0, 0, 0)
这个数组的长度就是3,但是存在一个问题就是如果我们使用追加函数。
如下所示:
scala> ab ++= Array(1,3,4,5)
scala> ab
res1: Array[Int] = Array(0, 0, 0, 1, 3, 4, 5)
就离谱!它的长度还是变了。将我们追加的元素放了进去。不知道是怎么想的。
你还会好奇是不是因为var或者val的问题?
我们再来试一下:
使用上文定义的数组,我来实现一个操作:
scala> ab(1)=1
scala> ab
res3: Array[Int] = Array(0, 1, 0, 1, 3, 4, 5)
果然内容被修改了。
我们再来定义一个val的数组来试一试。
scala> val ab2= new Array[Int](3)
ab2: Array[Int] = Array(0, 0, 0)
里面的内容能不能修改呢?
scala> ab2(2)=1
scala> ab2
res10: Array[Int] = Array(0, 0, 1)
也是可以的!那么val到底是什么呢?
scala> ab2++=Array(1,2,3,4)
<console>:13: error: value ++= is not a member of Array[Int]
Expression does not convert to assignment because receiver is not assignable. ab2++=Array(1,2,3,4)
竟然报错啦!不过你可以意识到一个事情,实际上对于引用类型来说,val,var的实际区别在于其引用对象是否发生了修改,引用的对象的内容发生修改也是完全没有问题的!所以上文实际上是新的一个Array对象,并不是原来的长度发生了变化。
元组和zip操作
元组的定义很简单,Scala的元组是对多个不同类型对象的一种简单封装,它将不同 的值用小括号括起来,并用逗号作分隔,即表示元组。
val tuple=(元素,元素...)
举个例子:
scala> val tuple_names=("jszszzy","jszslxl")
tuple_names: (String, String) = (jszszzy,jszslxl)
需要注意的是访问成员的时候需要如下表达式:
scala> tuple_names._1
res15: String = jszszzy
Zip操作
zip操作实际上是把多个集合中的元素关联起来,将其合并成一个个元组,再放到集合中。
举个例子:
scala> val names=Array("jszszzy","jszslxl")
names: Array[String] = Array(jszszzy, jszslxl)
scala> val scores=Array(1,2)
scores: Array[Int] = Array(1, 2)
scala> names.zip(scores)
res12: Array[(String, Int)] = Array((jszszzy,1), (jszslxl,2))
实际上每个Array中的元素变成了一个元组。
当然这个方法不能对两个元组使用,否则会报错。
scala> tuple_scores.zip(tuple_names)
<console>:14: error: value zip is not a member of (Int, Int)
tuple_scores.zip(tuple_names)
集合
在Scala中,集合有三大类: List、Set以及Map,所有的集合都扩展自Iterable特质 。 Scala 集合分为可变的(mutable)和不可变(immutable)的 集合:
➢ 可变集合可以在适当的地方被更新或扩展,意味着可以对 集合进行修改、添加、移除元素
➢ 不可变集合类,初始化后就永远不会改变。
举个例子:
// 字符串
val fruit: List[String] =List("apples","oranges","pears")
// 整型
val nums: List[Int] = List(1, 2, 3, 4)
// 空
val empty: List[Nothing] = List()
// 二维列表
val dim: List[List[Int]] =
List(
List(1, 0, 0),
List(0, 1, 0),
List(0, 0, 1)
)
在Scala中,Set是没有重复对象的集合,所有元素都是唯一 的。默认情况下,Scala 使用不可变Set集合,若想使用可变的 Set集合,则需要引入 scala.collection.mutable.Set 包。
举个例子:
val set: Set[Int] = Set(1,2,3,4,5)
map
在Scala中,Map是一种可迭代的键值对(key/value)结构, 并且键是唯一的,值不一定是唯一的,所有的值都是通过键来获取 的。Map中所有元素的键与值都存在一种对应关系,这种关系即为 映射。Map有两种类型,可变集合与不可变集合,默认是不可变 Map 。 若 需 要 使 用 可 变 的 Map 集 合 , 则 需 要 引 入 import scala.collection.mutable.Map 类。
举个例子:
var A:Map[Char,Int] = Map(键 -> 值,键 -> 值...)
类的定义:
无论是在Scala中还是Java中,类都是对象的抽象,而对象都是类的具体实例;类不占用内存,而对象占用存储空间。由于面向对象的核心是对 象,若想要在应用程序中使用对象,就必须得先创建一个类。类是用于描 述一组对象的共同特征和行为。
在 Scala 中定义类时需要输入 class 关键字,整个类定义体包含在最外层的一对大括号中 ({…})。事实上,这个类定义体同样也是这个类的主构造函数。假如需要将参数传递给这个构造函数,就要在类名之后输入参数列表。
class 类名 (参数列表)
Scala类的定义主体就是类的构造器,称为主构造器,在类名之后用圆括号列出主构造 器的参数列表 . 主构造器的参数前可以使用val或var关键字,Scala内部将自动为这些参数创建私有字段, 并提供对应的访问方法:
举个例子:
scala> class Person(val name:String)
defined class Person
scala> val jszszzy = new Person("Jszszzy")
jszszzy: Person = Person@55f4f59a
//访问对应的成员属性,虽然是私有的但是默认提供了对应的访问方法。
scala> jszszzy.name
res14: String = Jszszzy
scala> jszszzy.name="Jszslxl"
<console>:12: error: reassignment to val
jszszzy.name="Jszslxl"
辅助构造方法
辅助构造方法使用this来作为方法名,this的返回类型为Unit,其定义格式如下:
class 类名{
def this(参数){
this(主构造器参数)
this.属性 = 参数;
}
}
每个辅助构造器的第一个表达式必须是调用一个此前已经定义的辅助构造器或主构造器, 调用的形式为“this(参数列表)”
单例对象与main
与Java不同的是,Scala中提供了object这个关键字用来实现单例模式,使用关键字object创 建的对象为单例对象。你如果在类的文件中直接定义一个mian方法是不能直接运行的,在IDEA中会报错:
package priv.jszszzy.test
class HelloWorld
{
var myVar : String ="Hello"
val myVal : String = "World"
def main(strings: Array[String]): Unit =
{
println(myVar + myVal)
}
}
ERROR: main 方法不是类 priv.jszszzy.test.HelloWorld 中的static, 请将 main 方法定义为: public static void main(String[] args)
但是scala没有static,这个其使用java虚拟机运行有很大关系,你需要这样定义:
package priv.jszszzy.test
object HelloWorld
{
var myVar : String ="Hello"
val myVal : String = "World"
def main(strings: Array[String]): Unit =
{
println(myVar + myVal)
}
}
由此可以看出,其想要main的入口方法需要一个object的单例类,scala 将单例模式视为本语言的第一等级成员。尽管我们声明了一个类,不过 Scala 运行时只会创建 HelloWorld的一个实例。也就是说,你无法 通过 new 创建 HelloWorld 对象。就好像 Java 使用静态类型一样,其他语言使用类成员(class-level member),Scala 则使用对象进行处理。由于 HelloWorld 中并不包含状态信息,所以我们此 处的确不需要多个实例,使用单例便能满足需求。
伴生对象:
在一个源文件中有一个类和一个单例对象,若单例对象名与类名相同,则把 这个单例对象称作伴生对象(companion object),这个类则被称为是单例对象的伴生类(companion class)。类和伴生对象之间可以相互访问私有的方法和字段。
- class 中要访问 object 中的私有属性,直接以 object 名来 “点” 相应的变量或方法即可,可以参考下面例子;
- object 中要访问 class 中的私有属性,必须要通过 class 的对象引用来 “点” 相应变量或方法,可以参考下面例子。
package priv.jszszzy.test
class HelloWorld
{
private var myName : String ="companion class"
def test():Unit =
{
println(HelloWorld.myVal)
//调用伴生对象的成员
}
}
object HelloWorld
{
private var myVar : String ="Hello"
private val myVal : String = "World"
private var c_ClassName : HelloWorld =new HelloWorld();
def test():Unit =
{
println(HelloWorld.myVar)
}
def main(strings: Array[String]): Unit =
{
println(myVar + myVal)
//伴生对象的成员
println(c_ClassName.myName)
//伴生对象的方法
HelloWorld.test()
// 伴生类的方法
c_ClassName.test()
}
}
output:
HelloWorld
companion class
Hello
World
方法与函数:
对于大多数的面向对象编程语言而言,方法指的是类或对象中定义的函数。当调用方 法时,方法中的 this 引用会隐性地指向某一对象。当然,在大多数的 OOP 语言中, 方法调用的语法通常是 :
this.method_name(other_args)
本文中的“方法”也满足这一 常用规范。我们提到的“函数”尽管不是方法,但在某些时候通常会将方法也归入函 数。当前上下文能够认清它们的区别。
方法的定义:
def functionName ([参数列表]):[return type]=
{
function body
return [expr]
}
函数定义:
val functionName ([参数列表]):[return type]=
{
function body
return [expr]
}
方法的多参数列表:
这里的 draw 方法有两个参数列表,每个参数列表都有一个参数,而不是拥有一个 具有两个参数的参数列表。
package priv.jszszzy.test
object HelloWorld
{
private var myVar : String ="Hello"
private val myVal : String = "World"
def MultiArgs(a : Int)(b :Int):Unit =
{
println(a)
println(b)
}
def main(strings: Array[String]): Unit =
{
/*那么,为什么要允许多个参数列表呢?
当最后一个参数列表只包含一个表示函数的参数时,多个参数列表的形式拥有整齐的块结构语法。
以下是我们调用新的 draw 方法的表达 方式:*/
MultiArgs(1){2}
}
}
函数简写规则
- (1)return可以省略,Scala会使用方法体的最后一行代码作为返回值
- (2)返回值类型如果能够推断出来,那么可以省略
- (3)如果方法体只有一行代码,可以省略花括号
- (4)如果方法无参,则可以省略小括号。若定义方法时省略小括号,则调用该方法时,也需省略小括号;若定时方法时未省略,则调用时,可省可不省。
- (5)如果方法明确声明Unit,那么即使方法体中使用return关键字也不起作用
- (6)Scala如果想要自动推断无返回值,可以省略等号
- (7)如果方法明确使用return关键字,那么方法返回就不能使用自行推断了,需要声明返回值类型
类的继承:
-
Scala和Java类似,只允许继承一个父类
-
Java只能继承父类中非私有的属性和方法,而Scala可以继承父类中 的所有属性和方法。
//父类 class HelloWorld { private var myName : String ="companion class" def test():Unit = { println(HelloWorld.myVal) //调用伴生对象的成员 } } //子类 class HelloWorld_son extends HelloWorld { var myName :String = "HelloWorld_Son" override def test(): Unit =//需要加入override关键字,来重写非抽象方法 { println(myName); } } //主类用来运行函数 object HelloWorld { private var myVar : String ="Hello" private val myVal : String = "World" //类的继承演示代码 def extendsTest(): Unit = { var son :HelloWorld_son= new HelloWorld_son() son.test(); } def main(strings: Array[String]): Unit = { //调用继承的方法 extendsTest() } } output: HelloWorld_SonScala Trait(特征):
在Scala中,Trait(特质)的功能类似于Java中的接口,但Trait的 功能却比Java中的接口强大。例如,Trait可以对定义的字段和方法进行实现,而接口却不能。Scala中的Trait可以被类和对象使用关键字extends来继承。
定义方法:
//特质演示 trait HelloWorld_trait { val trait_member = "trait"//特质成员 def traitTest ()= println(trait_member)//特质方法 def traitAbstratTest() :Unit//特质抽象方法 }部分代码演示:
package priv.jszszzy.test //父类 class HelloWorld { private var myName : String ="companion class" def test():Unit = { println(HelloWorld.myVal) //调用伴生对象的成员 } } object HelloWorld extends HelloWorld_trait { private var myVar : String ="Hello" private val myVal : String = "World" def main(strings: Array[String]): Unit = { //调用重写后的抽象方法 HelloWorld.traitAbstratTest() } //重写特质的抽象方法 def traitAbstratTest(): Unit = { HelloWorld.traitTest() } } //特质演示 trait HelloWorld_trait { val trait_member = "trait" def traitTest ()= println(trait_member) def traitAbstratTest() :Unit }
模式匹配
每一个模式匹配都包含了一系列选项,每个都开始于case关键字,每个模式和表达式通过**=>**来分开。值得一说的是,case在执行完语句后就不会再去执行其他case。
object Test {
def main(args: Array[String]) {
println(matchTest("two"))
println(matchTest("test"))
println(matchTest(1))
println(matchTest(6))
}
def matchTest(x: Any): Any = x match
{
//对应整型数值 1
case 1 => "one"
//对应字符串值 two
case "two" => 2
//case 对应类型模式,用于判断传入的值是否为整型
case y: Int => "scala.Int"
//表示默认的全匹配备选项
case _ => "many"
}
}
样例类:
使用了case关键字的类定义就是样例类(case classes),样例类是种特殊的类,经过优化以用于模式匹配。
使用后会有如下自动生成。
- 构造器的每个参数都成为val,除非显式被声明为var,但是并不推荐这么做;
- 在伴生对象中提供了apply方法,所以可以不使用new关键字就可构建对象;
- 提供unapply方法使模式匹配可以工作;
- 生成toString、equals、hashCode和copy方法,除非显示给出这些方法的定义。
object HelloWorld extends HelloWorld_trait
{
def case_test(test : case_test): Unit =
{
test match
{
case x:case_test =>println("This is case")
case case_test("jszszzy") => println("This is zzy")
}
}
def main(strings: Array[String]): Unit =
{
//调用模板类测试方法
case_test(new case_test("jszszzy"));
}
}
//模式匹配演示
case class case_test( name :String)


![Android开发笔记——快速入门(壹)[系统架构和Android Studio安装]](https://img-blog.csdnimg.cn/051e8aafec4b4fafaafe7663af118d08.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5o2u6K-06L-Z5pivenp5,size_20,color_FFFFFF,t_70,g_se,x_16)
